机器学习中的神经网络 (1/3) [课程]
Neural Networks for Machine Learning (1/3) [Course]

All lectures
- Course information
- Lecture 1: Introduction
- Lecture 2: The Perceptron learning procedure
- Lecture 3: The backpropagation learning proccedure
- Lecture 4: Learning feature vectors for words
- Lecture 5: Object recognition with neural nets
- Lecture 6: Optimization: How to make the learning go faster
- Lecture 7: Recurrent neural networks
- Lecture 8: More recurrent neural networks
- Lecture 9: Ways to make neural networks generalize better
- Lecture 10: Combining multiple neural networks to improve generalization
- Lecture 11: Hopfield nets and Boltzmann machines
- Lecture 12: Restricted Boltzmann machines (RBMs)
- Lecture 13: Stacking RBMs to make Deep Belief Nets
- Lecture 14: Deep neural nets with generative pre-training
- Lecture 15: Modeling hierarchical structure with neural nets
- Lecture 16: Recent applications of deep neural nets
Course information
This course was given by Geoffrey Hinton, University of Toronto. It is really a good course which connects all the terms that I used to saw here and there together, and gives intuitive explanations for abstract concepts. Not to mention that the professor currently is well recognized as the top researcher on machine learning. Highly recommended.
这门课的特点是精炼。各讲之间的逻辑关系明显,内容信息量大,每一句话都值得认真理解。我将自己对这门课的理解写成中文,即本系列博文。另外还有其他博主的本课程中文笔记,各位可参考。
Hinton 还曾在 Reddit 上回答了网友几十个问题。我挑了几个自己觉得深受启发的,贴在了这里。
Lecture 1: Introduction
1.1 我们为什么需要机器学习?
大家都知道,只要你能把一个任务编写成代码,就能让电脑替你完成这个任务。然而对于某些任务,你很难把它写成具体的代码。什么样的任务呢?
- 我们能够轻松完成这个任务,但说不清自己的大脑是怎么实现的;即使可以,描述出来也是相当复杂的。例如:辨认不同人的面孔,手写数字识别(见Fig1.1-1)
- 没有明显规则、需要通过蛛丝马迹来推测的任务。例如:银行监控信用卡诈骗事件
- 情况在随时改变的任务。例如:预测股票涨跌

Fig1.1-1 MNIST task.
于是,我们的思维需要更上一层楼。与其直接写执行该任务的程序,不如写另外一种程序:它能根据我们提供的输入来进行自我调整,直到符合任务要求。如果输入有改变,那么这种程序也会跟着变。这种程序的样子长得和经典程序不同,它的核心不是一行行结构精巧的语句,而是由训练产生的大量数字。毕竟,现在计算和数据的成本远远比雇程序猿写代码的成本低。这就是“机器学习(Machine Learning)”。机器学习的典型任务有:
- 模式识别:真实场景下的物体、面孔身份或表情、语音
- 异常监测:信用卡交易异常、核电站传感器读数异常
- 预测:股市或外汇走势、某个消费者可能会喜欢什么样的电影
而在众多的机器学习方法中,(人工)神经网络(Neural Network)近年来的表现十分惊艳:用神经网络方法完成的任务的准确度,相较于其他方法,有质的飞跃。
1.2 什么是神经网络?
为什么要关心在生命体内,神经如何进行计算?
- 为了理解真实的脑子是如何工作的。因为生物脑很大、很复杂,而且如果向里面扎入检测仪器,脑子就会死,所以需要用电脑进行仿真实验
- 因为生物脑的计算是并行、可变的,这与串行计算的电脑很不相同,所以研究生物脑可以为计算机科学家们带来启发。如果从这一点出发,那么我们应该关注大脑擅长而电脑不擅长的问题(如:视觉),而不应该关注电脑擅长而大脑不擅长的问题(如:加减乘除等运算)
- 受到生物脑启发而开发出来的算法,有的虽然并不完全符合生物运行机制,但确实能够解决实际问题,也是很有意义的
人工神经网络受到了生物脑的以下几点启发:
- 神经元相互连接。每个神经元可以接受来自其他神经元的输入,也可以向其他神经元输出信号
- 神经元之间的连接有不同的强度,可以用一个实数来表示。而且连接有两种功能:兴奋性和抑制性,分别用正负号+/-来表示
- 神经元之间的连接强度在学习过程中可以被改变
- 脑内神经元的数量巨大,大脑皮层各区的潜能很相似,从而能够完成灵活多样的任务
例如 Fig1.2-1,仅仅三个神经元就可以实现 AND(与)的计算。
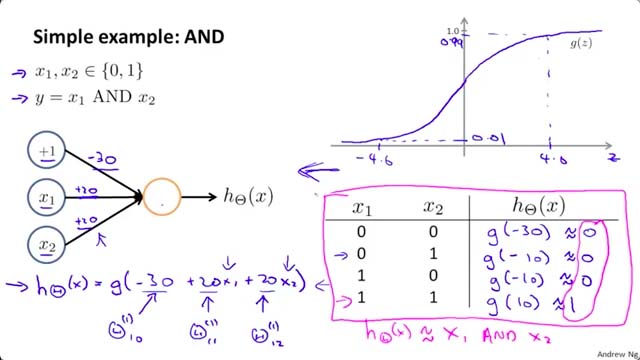
Fig1.2-1 Neurons for AND computation. From Course “Machine Learning” by Andrew Ng
1.3 一些简单的神经元模型
要为一个东西建模,我们就必须将其理想化,因为:
- 只有将复杂但不重要的大量细节去掉,我们才能理解主要的原理
- 简单的模型便于我们将数学工具用在上面、利用相似系统的已有研究成果
- 一旦我们理解了主要原理,把它复杂化、令其更贴近真实系统就变得很容易了
- 即使模型明显与真实系统不符,理解它也是很有价值的
Linear Neurons
每个神经元的输出是其输入的加权和(Fig1.3-1),即:输出 = ( 各输入 x 连接强度 ) 之和。这个模型很简单,但应用很受局限。
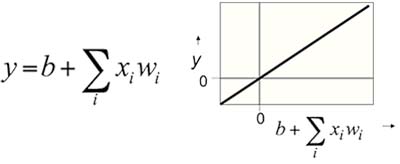
Fig1.3-1 Linear Neurons.
Binary Threshold Neurons
在 Linear Neurons 的基础上,加入阈值机制。即,只有当输入的加权和超过阈值时,神经元才被激活并输出 1,否则输出为 0(Fig1.3-2)。式子中表示阈值的是 b(bias,“误差”),即 -b = 阈值。
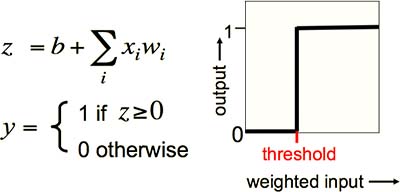
Fig1.3-2 Binary Threshold Neurons.
Rectified Linear Neurons
又叫 Linear Threshold Neurons。结合了 Linear Neurons 和 Binary Threshold Neurons。即,只有当输入的加权和低于阈值时,神经元输出为 0,否则输出等于输入的线性和(Fig1.3-3)。
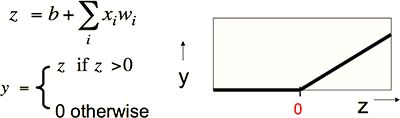
Fig1.3-3 Rectified Linear Neurons, or Linear Threshold Neurons.
Sigmoid Neurons
在 Binary Threshold Neurons 的基础上稍有调整。每个神经元的输出不再是简单的分段函数,而是其输入的加权和的 Sigmoid 函数(Fig1.3-4)。在这里,使用 Sigmoid Neurons 有以下几个好处:
- Sigmoid 函数是有界函数,其上下界分别为 1 和 0
- Sigmoid 函数处处可导,为后续的学习步骤提供了数学上的便利
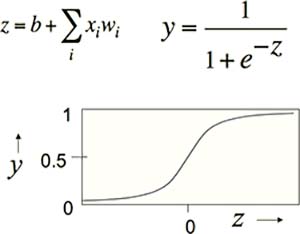
Fig1.3-4 Sigmoid Neurons.
Stochastic Binary Neurons
在 Sigmoid Neurons 的基础上,将 Sigmoid 函数视为“输出为 1 ”的概率分布。这样一来,神经元的输出就不完全依赖于输入,而是具有一定的随机性(Fig1.3-5)。
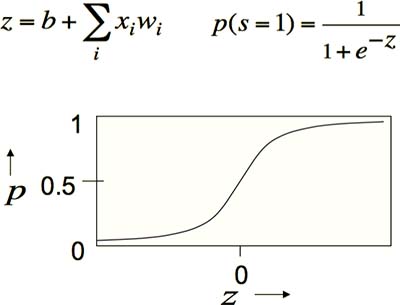
Fig1.3-5 Stochastic Binary Neurons.
1.4 三种机器学习类型
- Supervised Learning:根据输入预测输出。进而还可分为两种:
- Regression:输出是连续实数。例如,根据身高预测体重
- Classification:输出是离散类型。例如,根据肤色预测种族
- Reinforcement Learning:选择令回报最大化的行动。例如,机器人动作控制
- Unsupervised Learning:发现输入的内在特征,通常为了便于后续的监督学习或增强学习。例如,提取相同主题的文章的特征
Lecture 2: The Perceptron learning procedure
2.1 几种主要的神经网络架构
- Feed-forward Neural Networks(FNN) (Fig2.1-1A)
- 实际应用中最常见的类型
- 第一层神经元是输入层,最后一层神经元是输出层。每个神经元的输出无法回到自身
- 它对输入样本进行了一系列变换(transformation),从而改变了样本之间的相似度
- 上一层神经元的活动是下一层神经元的非线性函数
- 如果它的隐藏层多于一层,则被称为“深度”神经网络
- Recurrent Neural Networks(RNN) (Fig2.1-1B)
- 被认为是适用于序列数据的自然模型
- 神经元之间的连接是有向循环。神经元的输出可以回到自身。相当于很深的 FNN,只不过每两层神经元之间的连接强度总是一样的
- 这种结构使其具有复杂的动态变化,能够长时间“记住”信息,但是难以训练参数
- 更接近生命体机制
- Symmetrically Connected Networks
- 与 RNN 相似,只不过神经元连接是对称的。即,连接是双向的,且连接强度相等
- Hopfield 等发现,对称的网络比 RNN 分析起来更容易
- 但是由于它们遵循一个能量方程,所以它们能做的事情很有限
- 没有隐藏神经元的对称网络被称为“Hopfield Nets”
- 具有隐藏神经元的对称网络被称为“Boltzmann Machines”
- 它比 Hopfield Nets 更加强大
- 但是弱于 RNN
- 有一个优美的学习算法
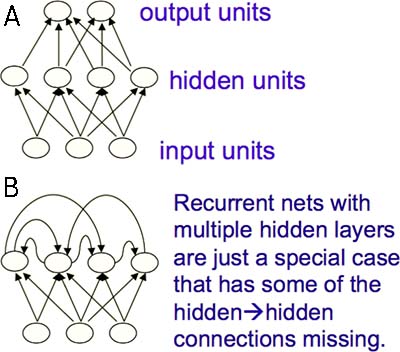
Fig2.1-1 Feed-forward Neural Networks (A) and Recurrent Neural Networks (B).
2.2 Perceptrons:第一代神经网络
Perceptron 的方法在1960年代早期因 Frank Rosenblatt 的工作变得广为人知的。然而到了1969年,Minsky 和 Papert 出版了一本名为“ Perceptrons ”的书,并于其中分析了 Perceptrons 能做什么、不能做什么,使得许多人错误地认为 Perceptrons 的局限性对于所有的神经网络都是成立的。从此神经网络模型遭遇了长达十几年的寒冬。直到1980年代,物理学家 Hopfield 发表的关于人工神经网络的文章引起了巨大反响,再加上计算机硬件技术的发展、其他机器学习方法遇到瓶颈,神经网络才又火起来。无论如何,Perceptrons 现在仍是被广泛使用的方法,特别是对于特征数量庞大的任务。
Perceptrons 的结构如下图:
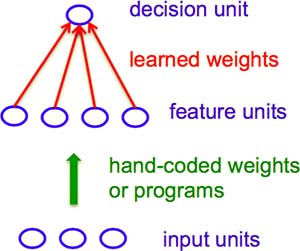
Fig2.2-1 The standard Perceptron architecture.
简单来说,对于一个“判断输入样本是类别 0 还是类别 1 ”的任务,Perceptrons 的工作步骤是:
- 人工提取输入向量的特征
- 学习,以决定每一个特征的权重 w。最后的输出为一个值。此学习过程将于后文阐述
- 如果这个值大于某个阈值,那么输入样本为类别 1,否则为类别 0
看到这里,你可能已经想起 Lecture 1 提到的 Binary Threshold Neurons:当输入的加权和超过阈值时,输出为 1,否则为 0;阈值用 b 来表示。为了计算的方便,我们将 b 看做一个特殊神经元和上层神经元的连接强度,这个特殊神经元的输出总是为 1,而阈值变成了0(Fig2.2-2)。
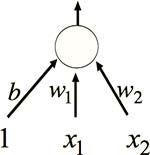
Fig2.2-2 Bias as weight.
如何训练 Perceptrons,得到合适的权重(神经元连接强度)呢?
- 初始化权重,例如 [5,5,5]
- 输入训练样本,例如 [2,2,2]
- 如果输出正确,则保持权重不变
- 如果输出错误,且输出为 0,则权重向量加上输入向量,得到新权重 [7,7,7]
- 如果输出错误,且输出为 1,则权重向量减去输入向量,得到新权重 [3,3,3]
- 重复上一步骤,依次输入其他训练样本,更新权重
这个训练方式能保证找到一套权重,以正确分类所有的训练样本,只要这套权重存在(重要前提)。为什么?请看下文:
2.3 从几何角度来理解 Perceptrons
为了便于说明,先让大家熟悉几个概念。学过线性代数的同学可能理解起来更轻松。
权重空间(weight space)是指数目确定的权重,其具体取值的所有可能性。每增加一个权重就增加了一维。例如,一个只有两个输入神经元的 Perceptrons 有两个权重。这两个权重的取值范围就构成了一个二维的权重空间,其中包括 [0,0],[1,2],[3.3,4.25],[-9,1000] 等等无穷个点。权重空间中的一点(向量),表示所有权重的一套具体值,例如 [4,3] 表示第一个权重取 4,第二个权重取 3。
由于在 Perceptrons 里,输入向量的维数和权重向量的维数相等,所以我们还有一个和权重空间维数相等的样本空间(sample space)。同样的,样本空间内的一个点(向量),表示了一个具体样本,例如 [2,2]。
我们希望将输入向量作为限制条件,将无穷大的权重空间缩小至特定范围,从而这个小范围内的任意一点就都是我们想找的权重了。现在,让我们把权重空间和样本空间重叠在一起,也就是说,把权重向量和输入向量置于同一个空间考虑(Fig2.3-1)。这样,我们就把问题转化为:当与输入向量是什么关系时,权重向量是一个好的向量?
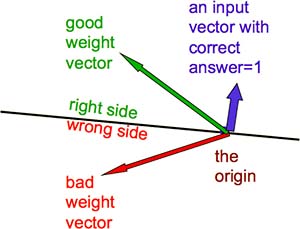
Fig2.3-1 What is a good weight vector.
现在,请回想一下 Perseptrons 的输出是怎么计算得到的:输入的加权和,即,输入向量和权重向量的内积。若内积为负,则为类别 0,否则为类别 1。而线性代数的知识告诉我们,当两个向量同向时,内积为正;当两个向量互为反向时,内积为负。所以我们要找的权重向量,必须与所有类别 1 的样本向量同向,而与所有类别 0 的样本向量反向。
由此可见,Perceptrons 的训练过程的本质是,对于每一个已知类别的训练样本:
- 若分类正确,则保持权重向量不变
- 若将类别 1 错判为类别 0,则将权重向量往正方向修正
- 若将类别 0 错判为类别 1,则将权重向量往负方向修正
但是有没有可能,满足所有条件的权重向量根本不存在呢?如图 Fig2.3-2,实心点是同一类别,空心点是另一类别。所以,Perceptrons 局限1:当样本是线性不可分时,不存在能够将所有训练样本正确分类的权重向量。一个典型例子是,将内容不同但是亮度相同的两张图像分别进行平移,生成两组样本。Perceptions 无法将这些样本正确分类,而模式识别的最重要功能就是识别平移图像。
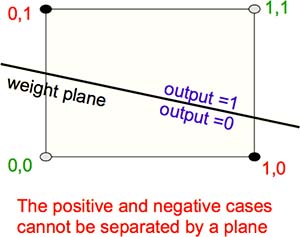
Fig2.3-2 When such weight vector does not exist.
除此之外,Perceptrons 局限2:需要人工构造特征,作为输入向量。如果能够知道特征,那么 Perceptrons 就是很强大的工具。
Perceptrons 局限3:因为没有隐藏层,输入-输出的对应关系很少,应用受限。如果仅仅单纯地增加几层线性神经元,那么效果不大,因为它们仍然是线性关系。所以我们需要加入多层隐藏神经元,且神经元之间的关系应是非线性的。然而这样一来,训练网络(学习权重)就变难得多了。下一讲,你会知道这样的网络如何进行学习。
Lecture 3: The backpropagation learning proccedure
3.1 Linear Neurons 的权重学习:The Delta-rule
为什么 Perceptrons 的学习过程不能套用到含有隐藏层的非线性网络?因为 Perceptrons 的成功建立在一个前提之上:两个好的权重向量之和,是一个更好的权重向量。然而这个前提无法推广到更复杂的网络。怎么办呢?我们需要换个思路。
回忆 Perceptrons 的学习过程:其本质是不断调整权重向量,使其更接近目标权重向量(对于每一个训练样本,其目标权重向量是已知的)。然而,现在目标权重向量变成未知的了。不过目标输出仍然是已知的。所以,与其让权重向量接近目标权重向量,还不如让实际输出接近目标输出来得更容易些,即,观察实际与目标的误差的大小。
容易想到,我们似乎可以用数学分析的方法将各权重解出来:对于线性神经元,根据“输出 = 输入的加权和”以及“误差 = 实际和目标之差的平方”,我们可以为每一个训练样本写出一个方程,然后找出令误差最小的方程组的解。问题解决了,但是实际上我们并不这样做。原因是:
- 从科学的角度来看,真实的神经元肯定不是通过解方程组来学习权重的
- 从工程的角度来看,我们需要一种能够推广到多层、非线性网络的方法:迭代法。虽然效率更低,却易于推广
举例说明一下迭代法。假设你在餐厅点了 2 份鱼、5 份薯条和 3 份番茄酱。你并不知道这些食物的单价,只知道收银员总共收了你 850 的钱(Fig3.1-1)。那么如何推测每样食物多少钱呢?
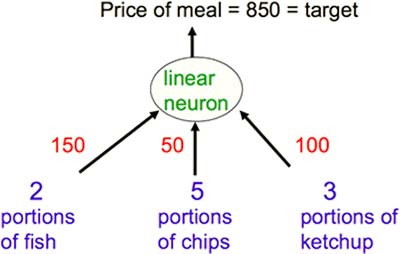
Fig3.1-1 The true weights used by the cashier.
首先,瞎猜个价格(比如,全为单价 50)。根据这个瞎猜的价格,总价应为 500,与实际相差 350(即,残差)。回忆 Perceptrons 的学习方法:当输出与目标不符时,根据输入向量来改变权重向量。在这里也是类似的,只不过要将输入向量稍作改变后,再调整权重向量。这种学习方法叫做 Delta-rule。如图 Fig3.1-2 。
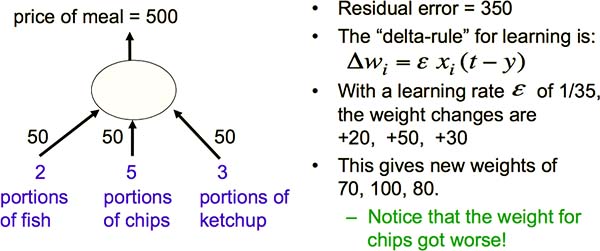
Fig3.1-2 Delta-rule with arbitrary initial weights.
对于迭代法的表现,人们会关心两个问题:
- 迭代法能够保证找到正确的权重向量吗?一方面,完美的解可能不存在;另一方面,如果学习速率足够小的话,我们可以接近最优解
- 权重的收敛速度如何?如果输入的某两项总是高度相关,那么收敛将会非常慢
另外,Delta-rule 分为两种:
- 批量(batch)学习。根据所有的训练样本计算总误差,整个学习过程仅更新一次权重
- 实时(online)学习。对每个训练样本都计算一个误差并更新权重,更新权重的次数与训练样本数相等
由前文可见,Delta-rule 与 Perceptrons 有相似性。那么它们之间的区别是什么呢?
- Perceptrons 的权重调整量 = 输入向量。且只有输出错误时,权重才会被调整
- Delta-rule 的权重调整量 = 输入向量 x 残差 x 学习速率(learning rate)。而选择学习速率是一件很恼人的事,原因是:
3.2 Linear Neurons 的误差曲面
稍加回忆可知,Sigmoid Neurons 的本质,是在 Linear Neurons 的基础上加入了阈值机制和 S 形的输出函数。所以在理解 Sigmoid Neurons 的学习方法之前,我们可以从更简单的 Linear Neurons 着手。
对于特定的任务,权重是有最优解的,即,取值越偏离最优解,误差越大。这个误差曲面的水平切面是椭圆形的,而纵向切面是碗状的,而我们的目标是到达碗底(Fig3.2-1)。
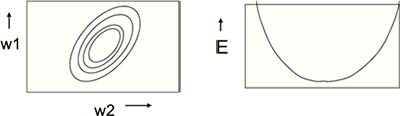
Fig3.2-1 The error surface is bowl-shape.
批量学习能够使权重沿着下降最快的路径进行改变(Fig3.2-2)。
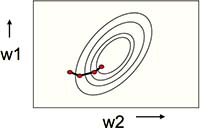
Fig3.2-2 Batch learning does steepest descent on the error surface.
实时学习则令权重在这条路径周围呈 Z 字形下降(Fig3.2-3)。
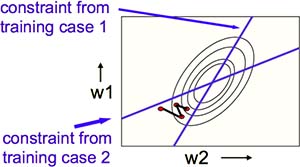
Fig3.2-3 Online learning zig-zags around the direction of steepest descent.
那么,什么情况下的权重学习会很慢呢?答案是:当误差曲面的水平切面是一个很长的椭圆、最陡路径的切线几乎与其总体走势垂直时。因为学习速率决定了每走一步的大小,所以在这种情况下,如果学习速率太大,权重就会一直在路径两边剧烈振荡、难以收敛;如果学习速率太小,需要的迭代次数太多,收敛依然很慢(Fig3.2-4)。
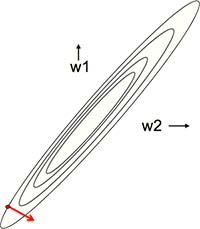
Fig3.2-4 Elongate error surfaces make slow learning.
至此,我们已经了解线性神经元是如何进行权重学习的了。那么,如何让非线性神经元 Sigmoid Neurons 进行权重学习呢?
3.3 权重学习:从 Linear Neurons 推广至 Sigmoid Neurons
已知在 Linear Neurons 的学习过程中,权重调整量 = 输入向量 x 残差 x 学习速率。表示如下:

Fig3.3-1 Deriving the delta-rule in Linear Neurons.
在 Sigmoid Neurons 的学习过程中,如果我们把误差对权重求偏导,可以得到与 Linear Neurons 相似的式子。推导过程如下:

Fig3.3-2 Deriving the delta-rule in Sigmoid Neurons.
也就是说,只要将 Linear Neurons 的权重调整量中的“学习速率”替换成 y(1-y),即是 Sigmoid Neurons 的权重调整量。推广完毕。
3.4 The Backpropagation Algorithm
前面我们已经知道如何调整单个权重,那么如何训练整个网络呢?自然地,你可能会想到:随机改变权重的值,如果能令输出更接近目标,则保存这个改变,直到神经网络能正确工作。实际上,这确实是 Reinforcement Learning 的一种形式。但是,这种方法非常低效,而且当学习进行到最后时,大的扰动反而令结果更糟。
所以我们的思维需要更上一层楼。由于“权重”对输出的作用不如“隐藏神经元活动”直接,所以与其扰动权重,不如直接扰动隐藏神经元活动状态,在得到理想的隐藏神经元活动后,再反推相应的权重取值。
然而,由于随机扰动效率很低,所以我们需要一个更聪明的策略。请回想一下 Delta-rule 的原理:根据输入向量和输出误差来调整权重。同理,我们何不据此来调整隐藏神经元的活动呢?即,隐藏神经元活动的调整量~输入向量和误差对活动的偏导。想法很好,然而唯一的问题是:输出向量和输入向量中间隔着多层隐藏神经元,我们无法直接套用 Delta-rule。当大家一筹莫展时,The Backpropagation Algorithm 的出现拯救了世界!
通过把玩数学魔法,有人发现了 Sigmoid Neurons 的神奇特性:当上层更接近输出、下层更接近输入时,通过上一层神经元活动的调整量可以计算下一层神经元活动的调整量,通过神经元活动可以计算权重。如图 Fig3.4-1,以下值可被依次求出:
- 上层神经元活动调整量 dE/dyj
- 下层神经元活动调整量 dE/dyi
- 下层神经元活动 yi
- 上层与下层之间权重的调整量 dE/dwij
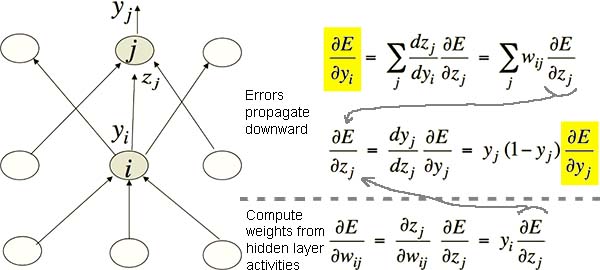
Fig3.4-1 The backpropagation algorithm. See how dE/dy is backpropagating.
核心的理论难关已被攻破!那么还需考虑的事情仅剩:
- 优化问题:如何充分使用训练样本?
- 多久更新一次权重?
- 实时(online):一个训练样本更新一次
- 全批量(full batch):所有样本处理完后才更新一次
- 小批量(mini-batch):每次抽取部分样本并更新一次
- 多大的调整幅度?
- Use a fixed learning rate
- Adapt the global learning rate
- Adapt the learning rate on each connection separately
- Don’t use steepest descent
- 多久更新一次权重?
- 推广问题:如何保证训练好的网络在新样本上也能正确工作?
- 采样有误差,导致学习到的特征不具代表性
- 网络太复杂导致过拟合。可能的解决方法:
- Weight-decay
- Weight-sharing
- Early stopping
- Model averaging
- Bayesian fitting of neural nets
- Dropout
- Generative pre-training
啊!好不容易搞懂了一个,怎么又来俩!要不然……先轻松一下,看看神经网络怎么解决实际问题:学习语义、物体识别。等到了 Lecture 6 和 Lecture 9 再来纠结这两个问题吧?
Lecture 4: Learning feature vectors for words
4.1 “认亲戚”任务
现在有两个家谱(Fig4.1-1)。神经网络的任务是:推测两个人的关系,即使在训练样本中并没有这两个人的直接关系。比如,我们用“Colin has-father James, Colin has-mother Victoria”等信息训练神经网络。训练完毕后,当我们输入“Who is James‘ wife”时,它能够输出“Victoria”。
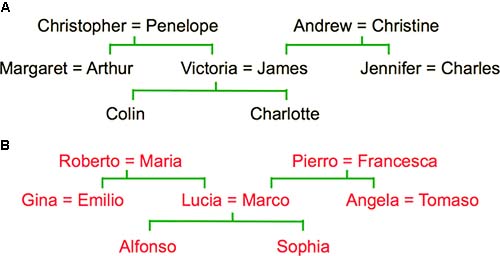
Fig4.1-1 Two family trees. Family A is from England. Family B is from Italy.
经过训练,神经网络自己学会了几个特征(Fig4.1-2),其中容易理解的有:特征 4 表示国籍,特征 5 表示第几代。
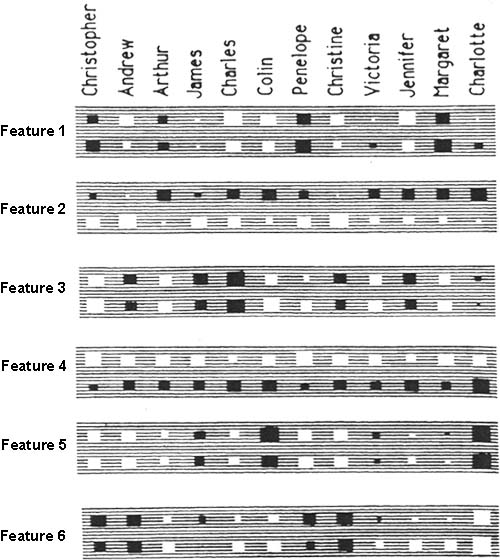
Fig4.1-2 Learned features.
于是你发现:哟嚯!这神经网络知道什么是“老婆”,它能理解概念了!
4.2 打个岔:认知科学
“认亲戚”任务可以引发我们对于“什么是概念”的探讨。长久以来有两个假说:
- 特征论:概念是一系列语义特征
- 结构论:概念的存在依赖于它与其他概念的关系
实际情况可能是二者的结合。因为我们能理解的概念中既有明确的、独立的“定义”,也有说不清的、与别的东西联系在一起的“常识”。
4.3 “语音识别”任务:神经概率语言模型
另一类任务是“语音识别”。它的的难点在于:在真实环境中,会出现一个词听上去和几个词都很像的情况,这时就需要根据上下文来推测正确的词。为了解决这个问题,以前的人们一直使用一种叫“三词(trigram)”的方法:统计在大量文本资料中,当相邻两个词为 a 和 b 时,接下来第三个词为 c 的频率,进而计算相对概率。然而这个方法有缺陷:三词组合的可能性数量实在过于庞大,而且里面大部分为零;另外,即使某个组合的出现概率的统计结果为零,事实上却仍有可能出现。仔细考虑后可以发现,“三词法”没有利用两个很重要的信息:语义、语法。通过上面的“认亲戚”的例子,我们已经见识了神经网络在“理解概念”上的潜力,所以自然想到用神经网络尝试解决这个问题。
在之前的神经网络的例子中,由于输出函数是 Sigmoid,所以输出值为一个接近于 0 或 1 的数。而在这个任务中,每个输出对应着一个词,输出值为“第三个词为该词”的概率,所有词的概率之和应等于 1,这是 Sigmoid 输出函数无法满足的。所以我们需要改用 Softmax 输出函数:输出和为 1,其输出对输入的偏导与 Sigmoid 函数的偏导一样(Fig4.3-1)。
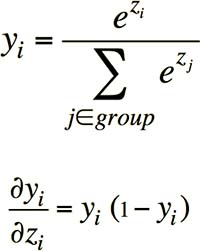
Fig4.3-1 The Softmax output function.
但是仍然存在一个问题:当目标输出为 1,而实际输出接近于 0 时,Softmax 的偏导将非常小,误差修正的速度将非常慢。这个问题的根源在于,我们使用了误差平方作为代价函数。如果将代价函数换成“交叉熵(cross-entropy)”,则其偏导为 yi - ti,补偿了 Softmax 偏导在两端的趋于平缓的问题,所以 Softmax 经常与 cross-entropy 配合使用(Fig4.3-2)。
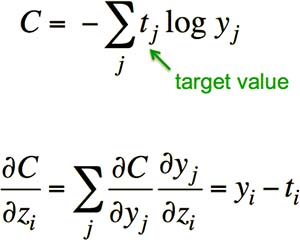
Fig4.3-2 Cross-entropy.
交叉熵是信息论里的概念,我觉得用在这里其实也没啥特严肃的道理,只是因为它能够提供一些数学上的便利罢了。没学过信息论的人估计无论如何都不会想到用交叉熵来解决这个问题。所以要想在学科交叉处创新,“先有问题再学知识”固然是效率最高的办法,但是有的问题需要“先有知识”才能联想到解决方案。
然而问题总是不绝。假设有100k个词,当我们把 Softmax 用在输出层时,最上层的每个隐藏神经元就会有100k个输出权重,这是很恐怖的数量级。那么如何解决大量输出的问题呢?
(此讲后面一堆没看懂,等看懂了再更新)
讲完了“语音识别”任务,下面来看看“物体识别”任务。
Lecture 5: Object recognition with neural nets
5.1 物体识别为什么难?
- 分割问题:真实场景中许多东西都混杂在一起。一方面需要判断哪个区域属于同一个物体,另一方面物体可能因为某些部位被遮挡而不完整
- 光照问题:物体的明暗、色调会受光照影响
- 功能可见性:“同一个物体”通常是以功能是否相同来定义的,而非外形是否相似
- 数据组织错误:比如将病人的“年龄”误录入在“体重”一栏
- 畸变问题:物体的平面图像可能进行非仿射变换。而仿射变换的物体识别(即视觉不变性)曾经是难题,直到最近才被解决。详见:
5.2 如何达到“视觉不变”?
视觉不变是指,即使对图案进行平移、缩放、翻转、旋转和错切等仿射变换,大脑仍然能够判断“这是同一个物体”。这是计算机感知技术中最主要的困难,长久以来没有公认的良策。由于生物脑太擅长这个任务,所以许多人认为这并没有什么了不起。为了解决这个问题,人们开发了多种方法:
- 利用稳定(即经过变换后仍然不变)的特征。但是要避免误将其他物体的特征包括进来
- 用暴力尝试法在物体周围画一个框,然后进行变换。但是只有先知道物体的样子才能画框。这是一个“鸡生蛋蛋生鸡”的问题
- 利用有明确姿势的、有层级关系的部件相对于摄像头的位置。将于课程稍后解释
- 对同一特征运用多个检测单元。这叫“ Convolutional Neural Networks(CNN)”,是现在神经网络应用的主流方法。详见下文
5.3 Convolutional Neural Networks
对一个可能发生了平移的图案,我们可以将其特征检测单元复制好几个,置于不同位置上,使得无论图案平移到哪里,至少有一个单元能够检测出来(Fig5.3-1)。当然,除了“位置”,我们也可以在“大小”和“方向”的层面复制检测单元,但这很难,而且代价很高。另外,我们还可以对同一个图案同时检测多个特征。总之,从本质上看,CNN 只不过比基本神经网络在寻找目标权重的过程中多了一些限制条件。
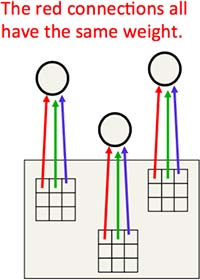
Fig5.3-1 Convolutional Neural Networks.
事实上,只要将 Backpropagation Algorithm 稍加修改,便能实现 CNN:按照原方法计算每个权重的调整量后,令处于不同位置上的检测单元的实际调整量相等,即,对应权重的调整量之和。这样一来,只要某一处的检测单元能够满足条件,则所有位置上的检测单元都应是满足条件的(Fig5.3-2)。
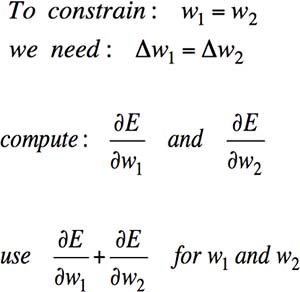
Fig5.3-2 Constraints in Convolutional Neural Networks.
一个著名的成功例子是纽约大学的 Yann LeCun 于 1989 年开发的 LeNet,当时被用于美国 10% 的支票号码识别(Fig5.3-3)。
![]()

Fig5.3-3 LeNet using Convolutional Neural Networks.
通过 LeNet 可知,关于任务的先验知识可以指导我们设计出更好的网络,如:权重的限制条件、网络连通程度、神经元激活函数等。虽然这比人工设计特征更好地保留了神经网络方法的优势,但是仍令网络或多或少地倾向于某类任务。另一种利用先验知识的方法是,生成更大的训练集,比如将训练集中的图片进行仿射变换后作为额外的样本,用于训练神经网络。虽然这样很累人,也导致训练时间变长,但是能让深层神经网络自动发现一些可能连人类都无法完全理解的巧妙方法。
如果将识别任务,从平面的黑白的手写数字,扩展到立体的彩色的真实物体,那么我们会遇到新的困难:
- 待区分的类别增加了百倍(1000 vs 10)
- 像素点变多了百倍(256 x 256 彩色 vs 28 x 28 灰度)
- 照片是三维物体向二维平面的投影
- 需要将照片中的物体分割出来
- 同一张照片里有多个物体
在 ILSVRC-2012 图像分类竞赛中,多伦多大学的 Alex Krizhevsky 在 LeNet 的启发下,通过利用深层 CNN、GPU 和许多其他技巧,将错误率降低至 16.4%,超越第二名多达十个百分点。